The Compounding Loop
Why AI-Native Companies Have Something SaaS Never Had

In my last post, I made the case that the defensibility stack in AI has collapsed to two things: domain skills that compound across your customer base (Level 1) and customer-specific judgment that makes every deployment feel irreplaceable (Level 2). That framework tells you what to build. But it doesn’t fully explain why the best AI-native companies are pulling away from everyone else at a pace that looks nothing like SaaS.
The answer is a structural dynamic that SaaS never had. I’ve been calling it the compounding loop -- and once you see it, it changes how you evaluate every company, every category, and every investment in the AI era.
SaaS Had Distribution. AI Has the Loop.
The moats in SaaS were real, and they weren’t static -- I’d be lying if I said otherwise after a decade at Salesforce. Switching costs grew organically as customers embedded deeper. The ecosystem compounded: app marketplaces, SI partners, developer communities. And the integration depth with each customer increased as they added more users, more custom objects, more workflows, more automation rules. Those moats built billion-dollar companies.
But two things were always true about them. First, the moats compounded around the product, not inside it. With revenue growth came the ability to raise more money, hire more teams, and build a broader set of features to charge more and capture a larger portion of a customer’s tech stack. But each individual feature never got better. Never got more helpful. Partially because every feature in SaaS was inert -- there was no embedded intelligence in the product. The software didn’t take actions on behalf of the user downstream. The user had to apply their own intelligence and go do the work themselves. The product was a tool. A very sticky, very expensive, very deeply embedded tool -- but a tool that sat there waiting for a human to operate it.
And this is why I get impatient when people say “code moats are dead” as if that’s a revelation. That’s a lazy argument. There was never a code moat in SaaS -- not when there was a second similarly sized competitor in virtually every category. Salesforce and Microsoft. Workday and Oracle. ServiceNow and BMC. The code wasn’t what kept customers. The embeddedness was. The ecosystem was. The distribution was.
Second -- and this is the part that should keep every SaaS incumbent up at night -- that embeddedness is exactly what AI is here to eat. All those months of metadata customization. The workflow builders with their cascading and often conflicting sets of rules. The admin configurations that required dedicated headcount just to maintain. That entire layer of complexity -- which was the switching cost, the thing that made rip-and-replace feel impossible -- collapses when a user can simply tell an agent how they want things done and the system remembers. The moat that SaaS spent a decade building is being replaced by a user instruction and an agentic memory model.
AI-native companies work differently. For the first time, the product itself has embedded intelligence. It doesn’t just store data and wait for a human to act -- it reasons, it learns, it takes action on the user’s behalf. And that creates a compounding mechanism SaaS never had -- one that lives inside the product itself.
Every user interaction generates data. That data -- the prompts, the outputs, the corrections, the acceptances, the rejections -- becomes proprietary traces. Those traces feed training loops and reinforcement learning systems that make the agents more precise and more capable over time. Better agents drive more usage. More usage generates more traces. More traces deepen the training. And the loop accelerates.
This is not a theoretical framework. I’m watching it happen in real time across our portfolio and across the companies building on Anthropic, OpenAI, and every other foundation model provider. The companies that have figured out how to capture and compound this loop are separating from the pack in months, not years. And the companies that haven’t -- the ones shipping essentially static AI features on top of traditional architectures -- are discovering that “AI-powered” on the marketing page doesn’t mean AI-native in the product.
The Three Gears of the Loop
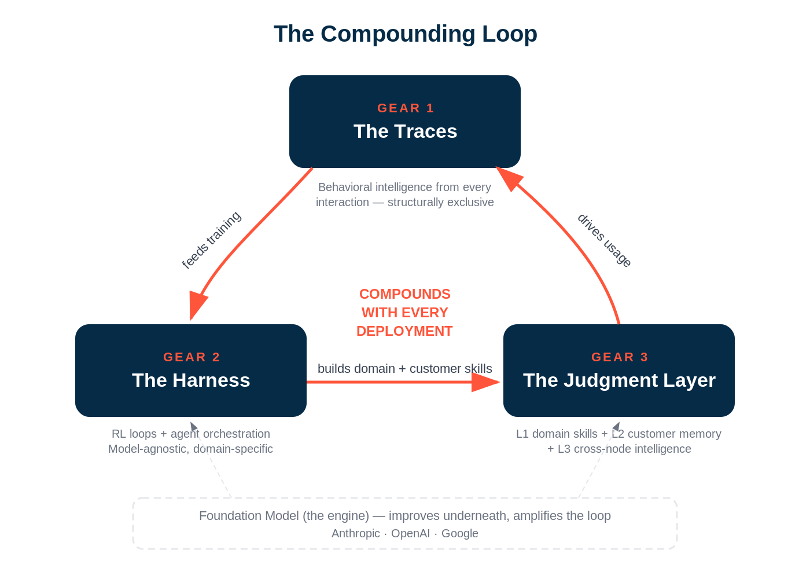
The compounding loop has three distinct gears, and the best companies are spinning all three simultaneously.
Gear 1: The Traces.
Every time a user interacts with your AI system -- every correction, every preference stated, every edge case surfaced, every output accepted or rejected -- you’re generating a proprietary trace. These traces are not data in the traditional SaaS sense. They’re not rows in a database. They’re behavioral intelligence -- a record of how your system performed in the real world and how humans responded.
The critical insight: traces are structurally exclusive. You can’t buy them. You can’t scrape them. You can’t generate them synthetically. They’re earned through deployments, one customer interaction at a time. A competitor who launches tomorrow starts with zero traces regardless of how good their foundation model is. And the gap compounds -- because your traces are already feeding the next two gears.
Gear 2: The Harness.
The traces alone aren’t the moat. The moat is what you build on top of the traces -- what we’ve started calling the harness. There are actually two harnesses, and the best companies own at least one.
The first is the RL harness -- the training loops, reward signals, and feedback systems that sit on top of whatever frontier model you’re using. This is how you turn raw traces into systematically better performance. Every time a user corrects an output, that correction becomes a training signal. Every time a user accepts an output in a specific context, that acceptance reinforces the behavior. The RL harness is what converts the raw material of traces into compound improvement.
The second is the agent harness -- the orchestration, context management, tool use, memory systems, and workflow logic that govern how your agents actually operate in the field. This is the operational intelligence: knowing which tools to use in which sequence, how to handle exceptions, when to escalate to a human, how to coordinate across multiple agents working on related tasks.
Because I keep getting asked “what does building a harness actually mean” -- let me be concrete about the architecture.
The RL harness has four components: a trace capture pipeline that logs every interaction with enough context to be useful for training, a reward signal framework that converts human feedback -- corrections, acceptances, rejections, explicit ratings -- into structured training data, an evaluation suite that measures agent performance against domain-specific benchmarks so you know the loop is actually working, and a fine-tuning or RLHF infrastructure that takes all of this and systematically improves the model’s behavior in your domain. This is the learning engine. Without it, you’re collecting traces and doing nothing with them.
The agent harness has its own four: an orchestration layer that determines which tools to call in which sequence for a given task, a context management system that decides what information the agent needs for each decision -- and critically, what it doesn’t need, because stuffing everything into context is the amateur move -- a memory architecture that maintains both short-term working memory for the current task and long-term memory about the customer and their preferences, and an escalation framework that knows when the agent is out of its depth and needs to hand off to a human, along with the logic for learning from how that human resolves the issue.
Here’s the line that matters for founders: the model providers are going to keep improving the raw reasoning, the context windows, the tool-use primitives, and increasingly the generic orchestration patterns. Anthropic, OpenAI, and Google are all getting better at making agents that can use tools, follow instructions, and reason through complex tasks. That’s the engine getting more powerful. But they will never build your domain-specific reward signals. They won’t design your proprietary evaluation criteria -- the benchmarks that measure whether an agent is good at your vertical’s specific tasks. They won’t build your customer-specific memory architecture. And they won’t encode the orchestration logic that reflects how a particular industry actually operates -- the exception handling, the regulatory guardrails, the workflow quirks that only someone deep in the domain would know to build.
The founder’s job is to own the layers that are domain-specific and let the model provider improve everything underneath. That’s what “the model is the engine, the harness is the car” actually means in practice. The engine keeps getting more powerful with every new release. The car -- your domain-specific RL harness and agent harness -- is what determines whether that power gets applied to the right problems in the right way. And the car is what the customer pays for.

Here’s why the harness matters more than the model: the next frontier model release will obsolete your fine-tuning. It won’t obsolete your harness. The harness is model-agnostic -- it makes any foundation model better in your specific domain. Companies that own the harness compound regardless of which model sits underneath. Companies that bet on model ownership are on a treadmill.
Gear 3: The Judgment Layer.
This is where gears 1 and 2 converge into something genuinely defensible -- the two-level judgment system I described in the last piece, but now you can see the mechanism that powers it.
Level 1 -- your domain skills -- gets better because traces from every customer feed back into the baseline capability. Your legal AI gets better at drafting demand letters because it’s seen thousands of them across hundreds of law firms. Your FP&A agent gets better at building revenue models because it’s processed edge cases from every industry vertical you serve. This is the network effect: more customers make the product better for every customer. And unlike SaaS network effects, which were primarily distribution advantages, this is a capability advantage. The product is actually, measurably, provably better.
Level 2 -- customer-specific judgment -- gets better because each customer’s traces accumulate into a visible memory model that reflects their way of doing things. The system learns that this CFO caps projections at 8%. That this sales team routes West Coast deals differently. That this legal department softens the indemnification clause for a specific client type. Every correction sharpens the model. Every interaction deepens the understanding. And because the returns are immediate -- correct the agent and it learns right now, not next quarter -- customers are motivated to keep feeding the system.
But there’s a third level of the judgment layer that I’ve been watching closely -- and it’s the one that gets me most excited about where this goes. Call it Level 3: cross-node intelligence.
Levels 1 and 2 describe a loop that gets smarter within a single customer or across a cohort of similar customers. Level 3 is what happens when multiple nodes in a vertical supply chain -- supplier, operator, buyer, and sometimes even the regulator -- all run agents through a shared platform. The product doesn’t just get smarter for one customer. It gets smarter about the relationships between customers and their counterparties. It starts to understand the dynamics of the chain itself.
Think about what this means concretely. A platform serving commercial construction might have the general contractor, the subcontractors, the materials suppliers, and the lender all operating through agents on the same system. The Level 1 skills get better at construction workflows generally. The Level 2 judgment learns how each specific company operates. But the Level 3 intelligence is something entirely different -- it’s learning how this GC works with this sub on this type of project in this region. It’s accumulating a cross-node graph of operational intelligence that no single participant could build on their own, no horizontal player goes deep enough to earn, and no competitor can replicate without getting all the same nodes onto their platform.
Now extend the thought one more step, because this is where it gets genuinely mind-blowing. Once each node in the chain has its own agent running on the shared platform, those agents don’t just accumulate intelligence independently. They start working with each other. The GC’s agent negotiates change orders directly with the sub’s agent. The sub’s agent coordinates material delivery timelines with the supplier’s agent. The lender’s agent monitors project milestones reported by all of the above and adjusts draw schedules accordingly. These aren’t humans emailing back and forth, losing context, playing phone tag, and waiting three days for a response. These are agents that share a common ontology, remember every prior interaction across the chain, and execute in minutes what used to take weeks of back-and-forth between humans at different companies.
The efficiency implications are staggering. Every handoff between companies -- every purchase order, every change order, every invoice, every compliance check, every status update -- is a friction point that exists because humans at different organizations have to align on context, verify information, and coordinate actions. When agents at each node handle those handoffs, operating on shared intelligence about how these specific counterparties work together, that friction doesn’t just decrease. It collapses. The coordination cost that defines how supply chains operate today -- the reason so much of the services economy exists -- gets compressed by an order of magnitude. And every interaction between those agents generates traces that make the next interaction faster, more accurate, and more autonomous. The cross-node loop doesn’t just compound within a single product. It compounds across the entire value chain simultaneously.
The switching cost here is extraordinary. A single customer leaving doesn’t just lose their own judgment layer -- they lose access to the collective intelligence about how their counterparties operate, and they lose the agent-to-agent coordination layer that was handling their cross-company workflows. That’s not your data walking out the door. It’s everyone else’s data walking out the door, and the operational efficiency that came with it.
I’ll go deeper on where this dynamic spins hardest when I map the loop onto our investment categories in the next piece. But the short version: the companies building platforms where agents operate across supply chain nodes -- not just within a single customer -- are building the deepest loops we’ve seen.
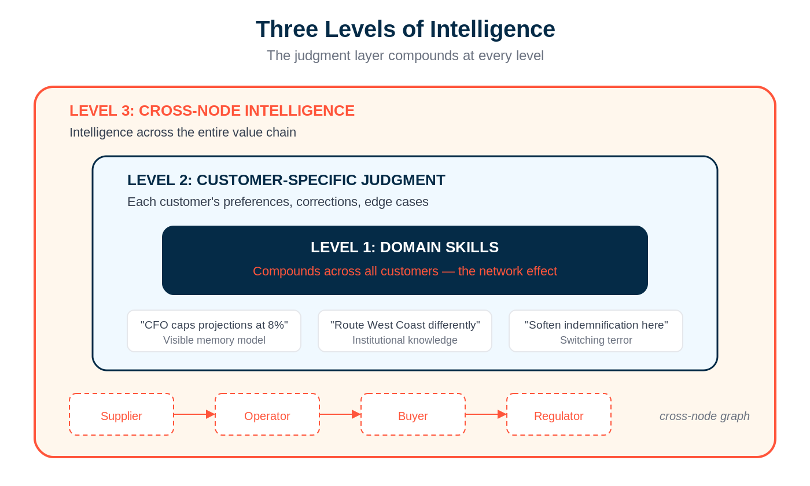
The three gears together create something that didn’t exist in SaaS: a product that gets meaningfully better the more it’s used, at the individual customer level, the aggregate level, and -- in the best cases -- across entire value chains simultaneously. The 1,000th customer makes the product measurably better for customer #1. That never happened in Salesforce.
Why This Changes the Economics
If you’re an investor -- or a founder thinking about fundraising -- the compounding loop changes the math in three ways that matter.
First, gross margins improve with scale instead of compressing.
This one surprises people. The conventional wisdom is that AI companies have a gross margin problem -- inference costs eat into every interaction, pushing margins down from the 80-85% SaaS benchmark toward 50-65%. And that’s true in the early innings. But as the compounding loop spins, something interesting happens: the agents get more precise. They make fewer errors. They require fewer tokens to produce the right output. They escalate to humans less often. The marginal cost of serving each customer decreases as the system gets smarter -- because a smarter agent is a cheaper agent.
The companies I’m watching that are furthest along the loop are seeing their unit economics improve quarter over quarter even as usage scales. That’s the opposite of what the “AI has a COGS problem” crowd predicted. The COGS problem is real for companies shipping generic AI features. It’s not real for companies that own the compounding loop.
Second, switching costs embed earlier and run deeper.
In SaaS, the switching cost was primarily your data. Export your CRM records, import them into the new system, deal with a few months of pain, done. The software never knew anything about you.
With the compounding loop, the switching cost is your judgment. Every trace, every correction, every preference, every edge case your team taught the system -- that’s institutional knowledge that lives in the vendor’s harness. And because the judgment layer is visible -- because customers can literally see everything they’ve taught the system -- they know exactly what they’d be walking away from.
I’ve started asking portfolio companies a question I’m calling the “switching terror metric”: if you pulled the agent out tomorrow, how much institutional knowledge walks out the door? How much operational damage happens? The companies where the answer is “catastrophic” are the ones with the deepest loops. The companies where the answer is “we’d figure it out in a week” don’t actually have a loop -- they have a feature.
Third, category winners separate faster.
In SaaS, the gap between #1 and #3 in a category was primarily a distribution gap -- the leader had more sales reps, better brand recognition, deeper integrations. But the #3 player’s product was often nearly as good. You could build a real business as the #3 player in a SaaS category.
In AI, the compounding loop makes the #1 player’s product measurably, provably better -- because they have more traces, a more refined harness, and a deeper judgment layer. The gap isn’t distribution. The gap is capability. And it widens with every deployment. Every customer the #1 player wins generates traces that make the product better, which wins more customers, which generates more traces. The #3 player’s product is objectively worse -- and the delta grows every quarter.
This is why AI categories consolidate faster than SaaS ever did. We’re watching it happen: the winners separate in months, not years. And once the loop is spinning, it’s nearly impossible for a latecomer to catch up -- because the traces can’t be bought, only earned.
What the Loop Looks Like in Practice
Let me make this concrete. I’ve been watching four patterns across the companies that are furthest along the compounding loop:
Pattern 1: The domain skills keep getting better without the engineering team shipping anything.
The product improves between releases because the RL harness is processing traces from the field. Customer #500 gets a better out-of-box experience than customer #100 did -- not because the team pushed a feature update, but because 400 deployments worth of traces have refined the baseline skills. This is radically different from SaaS, where the product only improved when engineers shipped code.
Pattern 2: Customer onboarding collapses.
Early customers took weeks to configure and train the system. Current customers are productive in days -- because the Level 1 domain skills have absorbed so many traces that the agent arrives already knowing how most companies in that vertical operate. The customer-specific Level 2 still needs to be built, but the starting point is dramatically higher. This compresses time-to-value, which accelerates adoption, which generates more traces.
Pattern 3: Expansion happens organically.
Once a customer has invested in teaching the system their way -- once Level 2 is deep -- they naturally expand to adjacent use cases. They don’t need to be sold on it. The agent already understands how their organization operates, so extending it to a new workflow is trivially easy compared to starting from scratch with a competitor. This is the FEED ME dynamic from the last piece, but now you can see why it works: the judgment layer the customer built is portable within the vendor’s ecosystem but not across vendors.
Pattern 4: The RL harness starts driving product decisions.
The most sophisticated companies are using their trace data to identify where the agents fail most often -- and building product specifically to close those gaps. The traces tell you what to build next. The product roadmap becomes data-driven in a way that SaaS product teams could only dream of -- because you have behavioral intelligence from thousands of real-world deployments telling you exactly where the system breaks.
What the Loop Does to the Product
There’s a consequence of the compounding loop that nobody seems to be talking about, and it surprised me: as the loop deepens, the product experience itself bifurcates -- and it goes in opposite directions depending on where you sit in the market.
Upmarket -- in the enterprise -- the application experience is going headless. As the judgment layer gets deeper and the agents get more capable, the traditional GUI becomes less important. The agent becomes the interface. Individual screens get generated on the fly via prompts. The value shifts from the visual experience to the quality of the structured data and domain logic exposed via API. Enterprise buyers don’t need a beautiful dashboard when they have an agent that can answer any question about their data, take action on their behalf, and coordinate with other agents across the organization. The moat moves from the GUI to the harness.
But downmarket -- in verticals serving SMBs and mid-market -- the trajectory reverses. The loop doesn’t make the product thinner. It makes the product more opinionated. More embedded. More essential. Instead of going headless, you go deeper. The AI doesn’t strip away the interface -- it enriches it, because the interface is the operating system for that business.
This is what I’ve started calling the TAM staircase, and the compounding loop is what powers each step. A vertical AI company starts as a point solution -- $50-200/month per seat, solving one specific problem. As the loop spins and the judgment layer deepens, the product climbs: all-in-one platform plus payments ($500-2K/month plus processing), then labor replacement ($2-5K/month, outcome-based pricing), and eventually -- at the top of the staircase -- business-in-a-box, where the pricing shifts to a percentage of revenue. Each step generates richer traces, builds deeper judgment, and makes the system harder to replace.
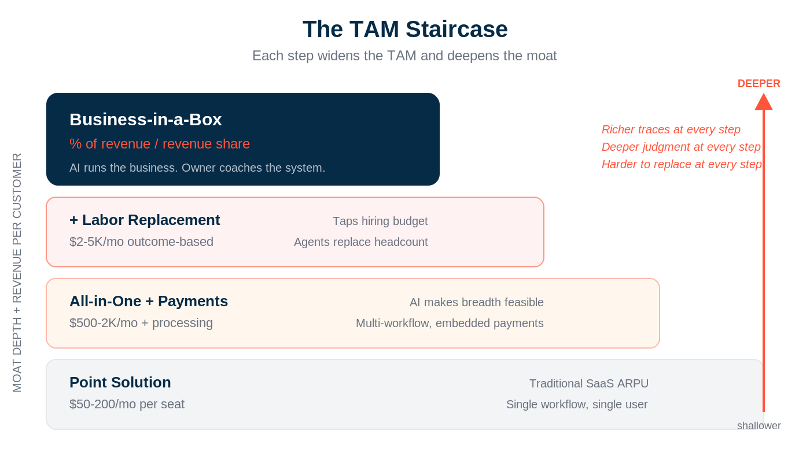
At the top of the staircase, the AI doesn’t just help run the business. It runs the business. The founder coaches the system; the system operates the company. Pricing, scheduling, maintenance, marketing, compliance, expansion decisions -- all handled by agents that have accumulated months or years of judgment about how this specific business operates. That’s a relationship no one switches away from. And that’s the opposite of headless. It’s everything.
This bifurcation matters for investors because it means the compounding loop creates fundamentally different business models at different segments of the market -- and both are massive. The headless enterprise play is about becoming the intelligence layer that every other system connects to. The business-in-a-box vertical play is about becoming the operating system that makes everything else unnecessary. Both are powered by the same three gears. Both compound with every deployment. They just express it differently.
The Founder’s Question: Where Do You Sit?
If you’re a founder, the compounding loop raises a critical question: where in the stack do you need to sit to capture the loop, versus handing it up to the foundation model provider?
This is the question I asked Paul Smith, Anthropic’s COO, at our recent LP summit -- and it’s the one every founder building on top of a model provider needs to wrestle with. Anthropic, OpenAI, and Google are all capturing traces from every API call. They’re building RL harnesses on top of those traces. They’re improving their foundation models with every interaction across every customer.
The answer -- and this is what separates the companies that will build durable value from the ones that will get commoditized -- is that the domain-specific loop is yours to own. The foundation model provider captures general intelligence. But the traces that matter for a legal AI company are the ones from legal workflows. The corrections that matter for an FP&A agent are the ones from actual financial planning sessions. The judgment layer for a recruiting AI is built from recruiting decisions, not from general language modeling.
If you’re building deep enough in a vertical -- if your domain ontology is rich, your edge cases are numerous, and your traces are specific to a problem space that the foundation model provider will never go deep enough to serve -- then the compounding loop is yours. The foundation model is the engine. Your domain-specific harness, traces, and judgment layer are the car. And the car is what the customer pays for.
And yes, the model providers are going vertical. This week Anthropic launched Claude for Legal -- 12 practice-area plugins, 20+ connectors to Westlaw, iManage, DocuSign, Everlaw, and the rest of the legal stack. Harvey’s CEO said what every founder building on a model provider should be thinking: they’ve known for years they’d eventually compete with the model companies. That moment is here.
But look at how Anthropic did it. They built the platform. The domain-specific harness -- the practice-area plugins, the workflow logic, the connectors to proprietary legal data -- was built by partners. Harvey, Thomson Reuters, LexisNexis, Legora. The companies with the traces from thousands of real-world legal engagements, the proprietary data that can’t be scraped from the internet, and the domain ontology that encodes how legal work actually gets done. Anthropic made the engine better. The domain layer still belongs to the companies that earned it.
The honest caveat is that neither layer is sufficient on its own. Proprietary domain ontology and structurally exclusive data are still required -- without them, your harness is just clever orchestration sitting on top of nothing the model provider can’t replicate, and the vertical launch is an extinction event, not a validation. But domain depth alone doesn’t compound either. A company sitting on years of proprietary data without a harness to turn that data into systematically better agent performance has a static asset, not a flywheel. The data appreciates in value, but it doesn’t drive the loop. It’s the harness on top of that domain depth that creates the compounding mechanism -- the thing that converts proprietary ontology and structurally exclusive data into traces, into training signals, into better judgment, into more usage, into more traces. Domain depth is the foundation. The harness is what makes it spin.
The question isn’t whether the model provider enters your space. It’s whether you have both layers -- the domain depth they can’t replicate and the harness that makes it compound -- deep enough that they need you more than you need them.
If you’re building a thin wrapper on top of a foundation model API -- if your traces aren’t domain-specific, if your harness isn’t differentiated, if a smart prompt engineer could replicate your product in a weekend -- then you don’t have a loop. You have a feature that’s one model update away from being absorbed.
The Technical Investment Filter
I’ll close with this, because it’s changed how we evaluate every deal that comes across our desk.
The old SaaS evaluation framework was built around metrics that assumed static products: ARR growth, net retention, CAC payback, gross margin. Those metrics still matter. But they don’t tell you whether a company has the compounding loop.
We are now asking five questions on top of the standard metrics:
How deep is the trace capture? Is the product generating proprietary behavioral data with every interaction -- or is it just passing prompts to an API and returning results? The companies that capture and store traces at the interaction level have the raw material for the loop. The ones that don’t are building on sand.
Who owns the harness? If the RL training and agent orchestration live in the foundation model provider’s infrastructure, the company is renting its advantage. If they own the harness -- the training loops, the reward signals, the orchestration logic -- they own the compound.
Is the judgment layer visible and compounding? Can you see the Level 1 domain skills getting measurably better quarter over quarter? Can customers see their Level 2 judgment model and are they actively investing in it? If the answer to both is yes, the loop is spinning.
What’s the switching terror metric at month twelve? If a customer tried to leave after a year, how much institutional knowledge would they lose? How many traces, corrections, and preferences would they be walking away from? If the answer is “not much” -- the loop isn’t deep enough.
Does the product get better between releases? This is the acid test. If the product only improves when engineers ship code, there’s no loop. If the product improves continuously because the RL harness is processing traces from the field -- that’s the compounding loop in action.
The context era taught us what information matters. The judgment era taught us who wins. The compounding loop is how they win -- and it’s why the best AI-native companies will look nothing like SaaS companies within three years.
The next piece in this series will map this framework onto the specific categories where we believe the loop spins hardest -- and where Bonfire is placing its bets.
Great piece Brett. One thought: the customer (with the power to cancel or buy more) needs to see the value of the service, and the risk of canceling - otherwise you might end up with CFO-driven churn and after-the-fact regrets. I’m often amazed how execs are unaware of the impact of the tech their teams are using.
This is so incredibly good. Wow.